Speech-Language Pathology Presentations
Email the First Author with your Questions & Comments
If bandwidth is exceeded, go directly to our YouTube Playlist
Alaryngeal Speech – Analysis of Two Forms of Voice Production in the Same Subject

Alaryngeal Speech – Analysis of Two Forms of Voice Production in the Same Subject
Susana Vaz-Freitas 1 2 3, MsC, PhD, SLP Elisabete Cardoso 4 5, MsC, ...

Categorization of Vocal Fry in Running Speech Katherine Proctor, Voice Foundation Symposium 2020
Katherine Proctor, B.S. (in progress), Ronald C. Scherer, Ph.D., ...

Fundamental Frequency and Intensity Effects on Cepstral Measures in Vowels from Connected Speech
Fundamental Frequency and Intensity Effects on Cepstral Measures in ...

How Do Tube Diameter and Vocal Tract Configuration affect Oral Pressure during Water Bubbling?
Karol Acevedo, SLP. Universidad San Sebastian/ Universidad de los ...

How Individuals Cope with Chronic Dysphonia
Jared Roduard Hermogenes, BAppSc(SpeechPathology)(Hons), The ...

Identity and Voice Therapy Outcomes:A Model for Adherence, Habilitation, and Rehabilitation of Voice
Marianna (Annie) Rubino, MFA, MS, CCC-SLP, PhD Student, University of ...

Impact of Hearing Protection and Background Noise on the Voice of Steam Train Engineers
Desi Gutierrez, BA, MA Graduate Student, Dept. of Communication ...
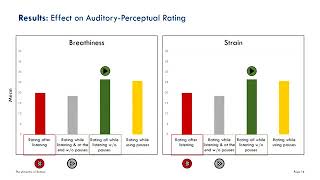
The Impact of Student Rating Preferences using an Online Auditory Perceptual Training Tool
A/Prof Cate Madill, Ph.D., BAppSc (Speech Pathology)HonsM1, BA (Hons), ...

Nasal and Vocal Tract Coupling: Variation of the Velopharyngeal Opening in 3-D Casts
Miriam Havel MD, Dept. of Otorhinolaryngology, Head&Neck Surgery, ...

Respiratory Muscle Strength Training for Patients with Presbyphonia
Maude Desjardins, PhD, Post-doctoral Researcher, Department of ...

Self-perceived Voice Problems in a Non-treatment Seeking Older Population in Hong Kong
Estella P.-M. Ma, Ph.D., Associate Professor, Human Communication ...

The Speech-Language Pathology First Contact Assessment for Voice Disorders
Christopher Payten, PhD Candidate, Gold Coast University Hospital and ...
